
#В чём моя проблема?
Я хочу иметь какие-то абстрактные чиселки рядом с правилами формальной грамматики, которые будут преобразовываться по каким-то абстрактным правилам (не обязательно умножение или сложение), для достижения каких-то целей.
#Что за цели?
Я пишу парсер при помощи которого будет аппроксимироваться естественный язык через Контекстно-Свободные грамматики. Очевидно, так как это аппроксимация, не может быть чего-то абсолютно верного и точного. Значит какие-то правила могут лучше аппроксимировать некоторые фразы, а какие-то хуже. Для этого мне нужны чиселки, чтобы они как-то преобразовывались, и чтобы на выходе получалось примерно такое: вот для этой фразы такой-то факт с вероятностью 57% правильный, для такой-то фразы с вероятностью 98% правильный.
#Почему чиселки абстрактные, что тебе нужно от них?
Хотелось получить удобный интерфейс задания этих чиселок, который можно логически трактовать и который можно легко написать, будучи пользователем парсера (то есть без вмешательства численных методов).
#Ну, например, существуют обычные вероятности - числа от 0 до 1, бери их да, умножай.
Нет. Обычные вероятности не подходят по нескольким причинам:
- Чем больше фраза, тем больше умножений чисел от
0до1, тем ближе результат к0. - В связи с этим абсолютные значения "вероятностей" не имеют никакого смысла.
- Задавать их неудобно, нужны какие-то магические числа
0.57,0.98,0.05. - Накладывается ограничение в виде того что сумма вероятностей для одного нетерминала должна быть
1. - Смотри пример в /199
Вроде разъяснил, дальше продолжу обычное повествование.
В /184 я предложил интерфейс описания "абстрактных чиселок", который можно логично трактовать:
+20%- значит что-то увеличивается на что-то, увеличивается на число больше что больше чем+10%-20%- аналогично верхнему уменьшается, и уменьшается сильнее, чем на-10%60%- задаёт обычную вероятность
Вскоре я понял что нельзя смешивать обычную вероятность и эти +20%, -20%. Потому что обычная вероятность их съедает, и вообще всё заражает собой.
Поэтому выкидываем её и добавляем элемент: 0% - он означает, что ничего не изменится.
Назовём эту величину "уверенность". И введём операцию объединения "уверенностей" под символом ★.
Теперь главная проблема состоит в том, чтобы определить как эти уверенности задавать, какие у них свойства и как вычислять ★.
Я решил что -20% должно мапиться в -0.2, +20% в +0.2, а в итоге область определения должна быть [-1; 1].
Я начал с создания такой функции.
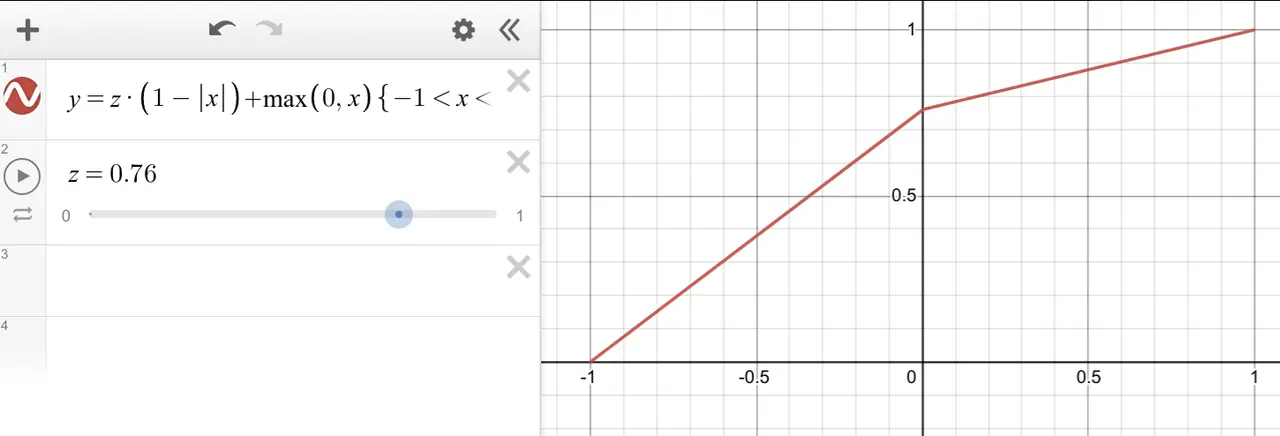

png
Её проблема в том что она не гладкая, и она даёт разные результаты в зависимости от порядка когда её применять. А ведь в грамматиках не задан конкретный порядок, и не знаешь когда надо выполнить ★, а когда нет. К тому же она получала данные в области [-1; 1], а возврщала в области [0; 1]. Но это легко поправляется.
Значит, самое главное свойство, которое мне нужно, это: (a ★ b) ★ c = (a ★ c) ★ b.
Далее я пытался гуглить, но безрезультатно. Пытался читать теорему Байеса, думать как её применить к своей задаче, тоже безрезультатно.
Затем я осознал, что я могу применить грубую силу!!! Я чёртов программист численных методов, я должен это использовать чтобы численно найти нужную мне функцию!
Итак, я должен был сделать следующую последовательность действий:
- Сформулировать свойства необходимой мне функции
- Запрограммировать расчёт выполнения этих свойств при помощи интегралов
- Найти библиотеку для задания гладких 2D функций по каким-то числам
- Использовать методы оптимизации, чтобы найти такие числа, которые на этих интегралах дают минимум
- Достаточно оптимизировать и использовать
Я думал что такой функции может не существовать, уж слишком хорошей она должна была быть.
Свойства я легко сформулировал, написал интеграл и начал тестировать. Моя линейная функция возвращала на этих свойствах 2. А идеальная функция должна 0. Самое плохое что там было - тройной интеграл для самого важного свойства (поэтому для точности с 10 точками требовалось 1000 вычислений функции).
Библиотеку для построения гладких 2D функций я не нашёл, поэтому пришлось применять свои знания с МКЭ, и самому программировать вычисление функции по числам-точкам.
Для методов оптимизации (нахождения минимума функции) я взял argmin-rs. Советую квазиньютоновские методы.
Затем я совместил это всё с методами оптимизации и...
Оно работало очень долго. Для задания 2D функции я требовал слишком много параметров, и многие из них были избыточны, так что времени тратилась уйма.
Затем я понял, что нужна визуализация! А тут как раз Антон рассказал про встраиваемый Питон в Rust! Немного повоевав с ним, я смог вывести получающуюся функцию через matplotlib, и даже plt.show() работало!
Я вывел график, и...
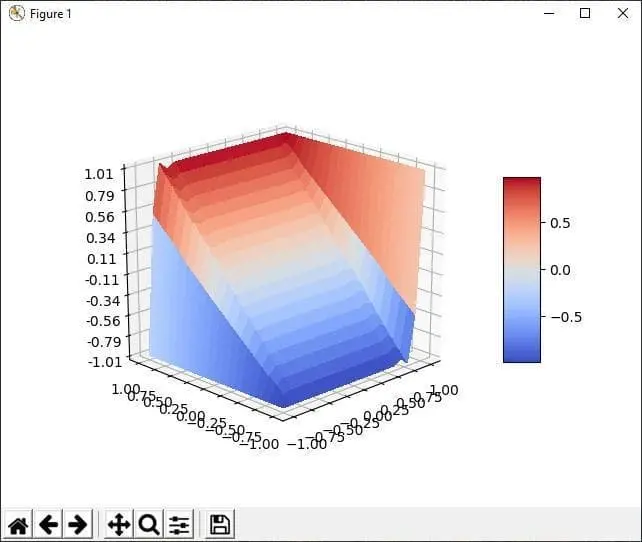
jpg
Функция получалась... ужасная, она была очень шумной, не монотонной, явно переобучалась где-то. Ну и метрика кое-как доходила до 0.04. Я ставил оптимизацию функции на несколько часов, и безрезультатно, в итоге у меня получалась полная чушь, да к тому же вырожденная, получалась функция, которая стремится сохранить первое значение.
Я сильно расстроился.
Но на следующий день мне пришло в голову, что на самом деле мои "веса" из /199, были очень даже подходящими! Они идеально подходили для отрезка от 0 до 1 и умножения 0.8 на 1.2, но были неудобны для отрезка от 1 до ∞. Тогда я решил просто сворачивать эту бесконечность до 1 путём деления. Тогда +20% превращалось в 1+1/(1-0.2)=2.25. И знаете что? Я получил идеальную функцию, которую хотел! Она идеально удовлетворяла всем свойствам и была очень даже гладкой. А ещё она симметричная: от -1 до 0 ведёт себя так же как от 0 до 1.
Эх, так просто. А я даже не верил что она существует.
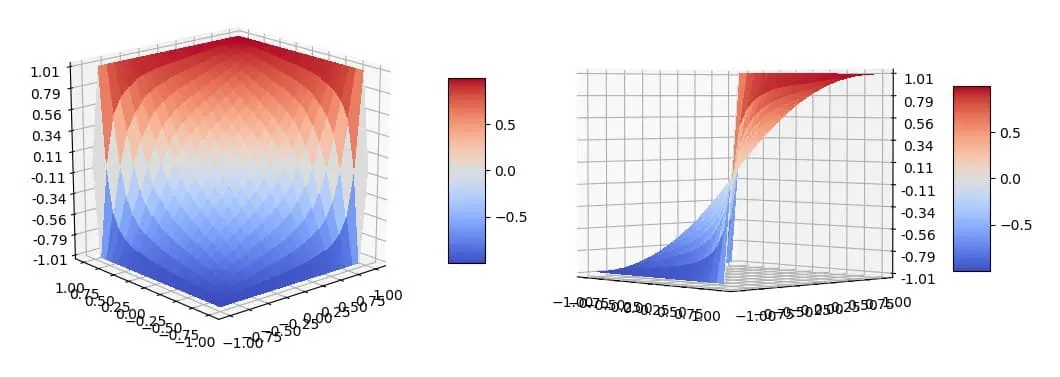
jpg
Вот она, моя идеальная функция ❤️
А покрутить её можно здесь.
Результат я опубликовал здесь: github:confidence, старался написать код очень красиво и безопасно. В итоге понял, float - это динамическая типизация на уровне процессора, и я хочу чтобы он был на алгебраических типах данных)))0)
Но это уже совсем другая история, и тема следующего поста...
#Отрезок [-1, 1]
Вообще я очень люблю отрезок [-1, 1].
Год назад, когда я писал курсовую по МКЭ, мне нужно было провести исследование того насколько хорошо метод работает на неравномерных квадратных сетках, построить графики или таблицы.
Если вы не знаете что такое неравномерная сетка, то вот иллюстрация (которую я нарисовал кодом). Свойство этой сетки в том, что каждый следующий элемент больше другого в c раз, где c - какое-то положительное число от 0 до ∞.
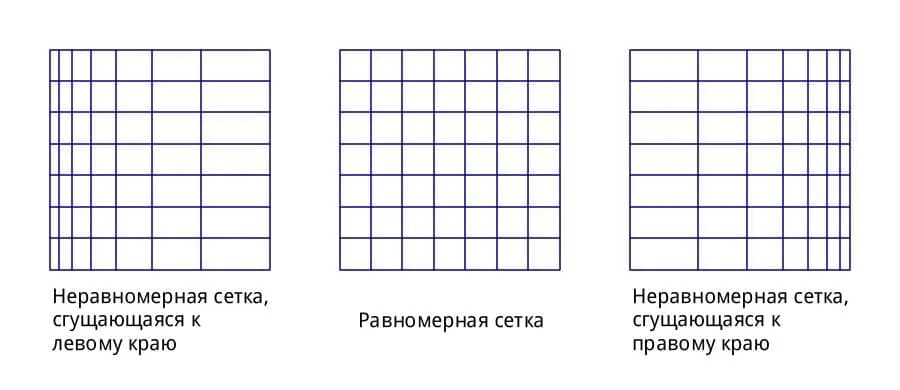
jpg
Все обычно строили таблицы, где брали несколько неравномерных сеток и точности на ней, и делали какие-то выводы. А я грёбаный перфекционист, я заставлял компьютер трудиться не покладая транзисторов, и поэтому перебирал с очень маленьким шагом всё что можно, и строил графики через латех.
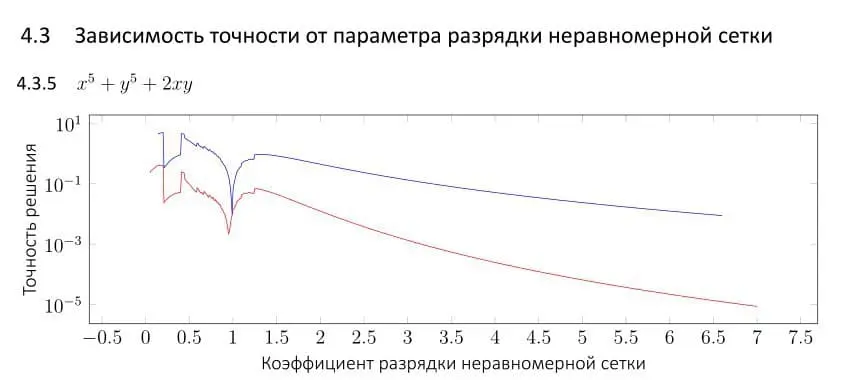
Сначала я, как и все задавал число c от 0 до ∞. Получается, чем ближе c к нулю, тем сгущённей сетка к правому краю, а чем ближе она к бесконечности, тем сгущённей к левому.
Но проводить исследования на чём-то до бесконечности не удобно, взгляните на этот график:
jpg
Где мне здесь остановиться? На 10^5? На 10^10? Делать экспоненциальное возрастание икса и логарифмическую шкалу? Непонятно. Тем более это очень неудобно логически воспринимать: несимметрично право и лево как-то получается.
Тогда я принял решение придумать такую функцию, которая позволяет задавать неравномерные сетки очень удобно, чтобы для значения коэффициента -1, сетка сгущалась к левому краю, а при значении коэффициента 1 сетка сгущалась к правому краю.

jpg
Придумал и описал в отчёте.
А вот так офигенно выглядят исследования где одновременно меняется параметр сетки по осям X и Y.
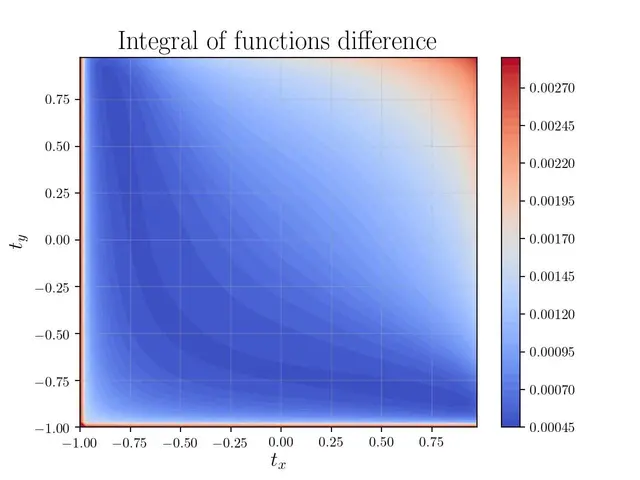
jpg
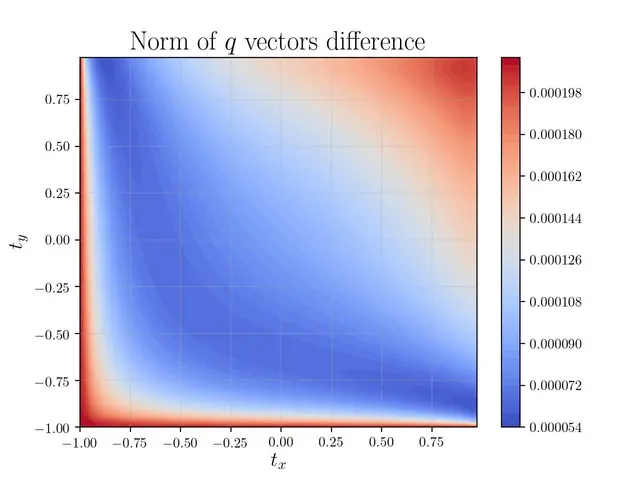
jpg
#Апдейт от 21.12.2024
Недавно вышла новая модель искусственного интеллекта o1, и я попросил её разработать функцию, которая бы решала эти вероятности, и она сделала очень красивую и маленькую альтернативную функцию, удовлетворяющую моим запросам. Ниже будет запрос и её решение. Когда я писал эту статью, я и подумать не мог чтобы какая-то автоматическая система смогла мне помочь в этой задаче. Воистину, мы вошли в новую эру технологий.
Посмотреть на эту функцию можно в desmos: https://www.desmos.com/calculator/gzejyiee3u
Диалог
Я нашёл один репозиторий, который вводит какую-то функцию умножения "уверенностей". Выведи функцию, которая бы удовлетворяла этим условиям, как бы она могла выглядеть? Размышляй и отвечай на английском.
# Confidence function
Предположим, мы пишем парсер, который для каждого правила грамматики задаёт вероятность. Если данное правило распарсилось, то мы умножаем эту вероятность к итоговой.
В таком случае проблема классических вероятностей, - чисел от 0 до 1, в том, что для большого размера парсируемого текста итоговая вероятность будет очень маленькой. И нам сложно оценить насколько мы уверенны в данном результате.
Здесь же представлен тип данных `confidence`, умножение которых позволяет представлять такую уверенность. У этого типа данных есть три разных состояния:
* Степень уверенности в том что гипотеза неверна
* Полная неуверенность
* Степень уверенности в том гипотеза верна
Его область определения `A = [-1, 1]`:
* На области `[-1, 0)` отображается уверенность в том что это неправильно. Чем ближе к `-1`, тем больше эта уверенность
* Элемент `0` означает что неизвестно правильно это или нет
* На области `(0, 1]` отображается уверенность в том что это правильно. Чем ближе к `1`, тем больше эта уверенность
Переопределён метод для умножения этих "уверенностей" друг на друга. Обозначим его как `P(a: A, b: A) -> A`, то есть функция принимает два аргумента из области определения `A`, и возвращает результат из этой же области определения. Эта функция обладает следующими свойствами:
* `P(x, 0) = x`
* `P(x, -1) = -1`
* `P(x, 1) = 1`
* `P(x, +y) >= x` - положительные увеличивают
* `P(x, -y) <= x` - отрицательные уменьшают
* `P(P(x, y), z) = P(P(x, z), y)` - независимо от порядка применения получается один и тот же результат. Это очень важно, потому что при парсинге возможно много вариантов в какой последовательности применить функцию, и от этого очень много зависит.
* `P(x, y)` относительно `y` монотонно возрастает.
* `P(x, y) = P(y, x)` - это свойство не нужно было для парсинга, но оно случайно появилось
Below is one example of a function that meets all the specified requirements. The idea is to interpret the "confidence" values in a way that allows us to combine them using an associative, commutative operation that respects the given constraints.
Key Insight:
If we think of these "confidences" as something like a "scaled opinion" measure on the interval , we can use a transformation related to the hyperbolic tangent function. Consider that maps real numbers to , and its inverse, , maps to all real numbers. When we apply , the confidence space becomes a linear space . In that linearized space, combining two confidences is just addition. Mapping back to gives us a nonlinear combination formula.
Derivation:
-
Define a transformation:
Here, .
-
In the transformed domain, "combining" two confidences and is just addition:
-
To get back to the original confidence domain:
Using the hyperbolic tangent addition formula:
we can substitute and :
Check the properties:
-
Identity with 0:
-
Absorbing elements -1 and 1:
-
Positive arguments increase the value: If , since , we have .
-
Negative arguments decrease the value: If , similarly .
-
Associativity: The operation is associative because addition in the domain is associative, and we are just transforming back and forth. Formally:
corresponds to:
-
Monotonicity in each argument: For fixed , as increases, increases (and vice versa) because both the numerator and denominator lead to a monotonic relationship. The -based structure preserves this.
-
Symmetry: Clearly .
Final Proposed Function:
with the understanding that for boundary cases like and , the function behaves as stated. This function satisfies all the listed requirements.