
#Введение
Программирование — не только написание кода, но и ещё планирование кода; определение того какие фичи нужны, а какие нет. У меня есть своя система, определяющая: как заниматься планированием программ, фич; как организовывать себя; как не забывать идеи. И я хочу в этой статье рассказать об этом. Что-то в этой системе придумал сам, что-то украл у других людей.
Эта статья может быть полезна начинающим программистам.
#На примере программы для изучения английских слов
Недавно я сделал программу с графическим интерфейсом для изучения английских слов. Перед её созданием сразу решил что напишу эту статью, и поэтому сразу начал замерять время каждого действия вместе с документированием написания кода, идей и выполнения туду-пунктов.
В итоге эту програму я довёл до абсолютного конца за ≈40 часов чистого времени. Мне не нужны какие-то фичи, ничего не болит. Что очень необычно для пет-проекта, ведь их главное свойство, что они начинаются, но никогда не заканчиваются.
#2Создание продукта
#3Сбор идей
Перед тем как делать какой-то проект вы всегда знаете что хотите получить программу с какими-то конкретными фичами, чтобы если вы сделали то-то, случалось это. Вы не знаете как она должна работать в каждой конкретной детали, но точно знаете что без каких-то деталей делать её нет смысла. Это всё надо записать и систематизировать, чтобы далее от этого отталкиваться при написании кода.
#4Беспорядочный сбор идей
Я беру файлик и называю его ideas.md. Теперь в нём будут лежать все идеи по данному проекту.
Сначала надо просто накидать всё что лежит в голове без всякого порядка. Я набросал, затем перечитывал это по многу раз и вносил те элементы что ещё не записал. Причём я записывал все идеи, даже самые безумные, мало ли что потом может пригодиться или случиться.
На беспорядочный сбор идей ушло 20 минут, и в результате получился такой файл:
(желательно его не читать, а просто увидеть масштаб)
@341bd26/ideas.md diff
- Хотелось бы загружать из текста и из субтитров, чтобы была кнопка, которая читает буфер обмена
- Чтобы при добавлении субтитров или текста, смотрелись все слова, и те что уже известны или выучены, не добавлялись, а новые слова показывались для дальнейшего добавления
- Интерфейс добавления слова
- Известные или выученные слова фильтруются
- Показывается английское слово
- Предлагается добавить его русский перевод вручную
- Либо есть кнопка "я уже знаю это слово"
- Чтобы для данного слова можно было видеть его контекст использования
- Чтобы в специальном файле можно было настравить раскладку клавиатуры, чтобы автоматически раскладка подстраивалась без переключения раскладки.
- Можно менять местами язык вопросов и ответов
- Как вводятся слова:
- Слово, которое не набиралось ни разу, надо сначала ввести n раз
- Слова, которые 5 раз отвечались правильно, считаются на сегодня законченными
- Слова, которые отвечаются неправильно, получают рейтинг -2
- Так же контроллируется дата, когда человек отвечал и как. Если некоторое слово долго не набиралось, то необходимо его повторить, причем если до этого повторение работало хорошо, то приоритет меньший.
- Только когда слово зарабатывает рейтинг кратный 5, то в записях фиксируется дата, когда это было сделано
- Приоритет слов для набора: Каждая категория сортируется в случайном порядке
- Слова, которые не набирались 5 раз
- Слова, которые имеют отрицательный рейтинг
- Слова, которые имеют рейтинг меньше 5
- Слова, которые имеют рейтинг выше 5, но весь этот рейтинг был заработан свыше 5 дней назад
- Слова, которые имеют рейтинг выше 10, но весь этот рейтинг был заработан свыше 5 дней назад
- Слова, которые имеют рейтинг выше 15, но весь этот рейтинг был заработан свыше 20 дней назад (слова, которые давно не повторялись)
- Слова, которые имеют рейтинг выше 20, но весь этот рейтинг был заработан свыше 20 дней назад
- Всё, больше точно не надо
- В центре экрана написано слово, которое надо перевести, ниже его написаны варианты ответа в виде "____ __", причем необходимо, чтобы _ были раздельны
- Не соотносится с многозначностью слов, пусть будет просто N полей с не важно какой длиной
- Как справляться с многозначностью слов
- Для данного английского слова хранится множество пар русских слов, аналогично наоборот
- Если сейчас показывается многозначное английское слово, то внизу нужно ввести все добавленные его русские смыслы
- В статистике оценивается пара (русское слово, английское слово)
- Если какое-то значение многозначного слова уже выучено или не требует повторения, то оно не показывается для ввода, оно просто показывается текстом, чтобы можно было понять какие смыслы введены, а какие нет
- Статистика
- Для каждого слова запоминается сколько раз его печатали, сколько правильно, сколько неправильно.
- Для каждого дня запоминается сколько слов за сегодня отработано по полной, сколько слов отработано вообще итд.
- Попробовать рисовать статистику через графики egui.
- Ведётся количество новых добавленных слов в день
- Где-то должно быть окошко чтобы посмотреть просто количество всех слов в системе, количество выученных слов и количество изучаемых слов
- При добавлении новых слов есть возможность говорить: я это слово знаю; это не знаю. Чтобы не учить лишний раз известные слова, и чтобы в других текстах они не добавлялись как неизвестные.
Кстати, на этом этапе крайне приятно владеть быстрой слепой печатью, чтобы писать много текста и не отвлекаться процессом печати.
#4Систематизация идей
У меня есть принцип, что что-то надо систематизировать и разбирать на категории только в двух случаях:
- Когда ты точно знаешь что эта категория использовалась ранее и она работает.
- У тебя есть критическая масса элементов этой категории.
Поэтому в прошлом пункте идеи писались беспорядочно, а теперь можно заняться их систематизацией, ведь только сейчас можно увидеть какие категории присутствуют, а какие отстутсвуют.
На это тоже ушло 20 минут.
Я хотел написать программу как можно быстрее, и как можно быстрее получать результат, поэтому я разделил идеи на разные категории, постарался выбрать такие идеи, чтобы реализовать первую рабочую версию (MVP) можно было максимально быстро.
Поэтому была создана категория «сложные идеи», куда я уносил то что хочу реализовать, но что точно не должно быть в первой итерации.
В итоге файл с идеями теперь выглядит так:
@5387e15/ideas.md diff
систематизированные идеи
Реализовать в первую очередь
- Общий интерфейс
- Добавление слов
- Через субтитры
.src - Через текст
- Через субтитры
- Окошко для выучивания слов показывается всегда и его нельзя закрыть, либо оно вообще привязано к фону
- Добавление слов
- Интерфейс получения слов из текста или субтитров
- Есть две кнопки: "добавить как текст", "добавить как субтитры"
- Интерфейс добавления слова
- Известные или выученные слова фильтруются
- Показывается английское слово
- Предлагается добавить его русский перевод вручную (новая строка означает новый смысл)
- Есть кнопка "добавить переводы слова"
- Либо есть кнопка "я уже знаю это слово"
- Интерфейс ввода слова
- Вверху написано английское (или русское) слово
- Внизу N полей для ввода всех многозначностей этого слова
- Некоторые поля могут быть серыми с уже написанными словами, так как эти слова выучены или не требуют сейчас повторения
- Для перехода вниз или проверки текущего слова можно нажать Enter
- Показывается правильно или неправильно введено слово только после введения всех слов
- Для кажого слова показывается точками сколько раз ещё предстоит его вводить на сегодня
- Порядок ввода слова
- Первые 2 раза слово вводится с подсказкой программы
- Затем 3 раза нужно ввести слово по памяти на сегодня
- Следующий раз ввести слово 5 раз нужно через день и более
- На этом этапе слово считается наполовину выученным
- Потом 5 раз через неделю и более
- Потом 5 раз через месяц и более
- После этого слово считается абсолютно выученным
- Каждая ошибка добавляет необходимость вводить ещё один лишний раз это слово
- Слова в очереди
- Русские и английские слова даются вперемешку
- Всё вперемешку
- Перебирается каждое слово и смотрится, нужно ли его набирать сегодня и сколько раз
- Как справляться с многозначностью слов
- Для данного английского слова хранится множество пар русских слов, аналогично наоборот
- В статистике оценивается пара (русское слово, английское слово)
- Статистика
- Для каждого слова запоминается:
- Сколько раз его печатали, сколько правильно, сколько неправильно
- Все даты майлстоунов, когда его печатали в первый день, во второй день, черз неделю, через месяц
- Для каждого слова запоминается:
сложные идеи
Реализовать потом
- Интерфейс получения слов из текста или субтитров
- Программа всегда видит буфер обмена, если открыто это окно
- Внизу серым написан текст, который сейчас находится в буфере обмена
- Показывается только 200 первых символов этого текста, далее ставится троеточие и подписано количество байт занимаемых всем текстом
- Интерфейс добавления слова
- Чтобы для данного слова можно было видеть его контекст использования
- Интерфейс статистики слова
- Когда добавлено (дата, количество дней назад)
- Сколько раз вводилось
- Сколько правильно, сколько неправильно
- Все майлстоуны (дней после добавления)
- Интерфейс ввода слова
- Есть кнопочка
(i)напротив каждого слова, на которую можно нажать и посмотреть статистику этого слова
- Есть кнопочка
- Интерфейс окна "раскладка клавиатуры"
- Тебя просят включить русский язык и ввести все английские буквы, как если бы они находились при включённом английском языке
- Аналогично при включённом английском языке просят ввести все русские буквы
- Таким образом программа запоминает раскладку клавиатуры и сохраняет её в настройки, чтобы потом использовать чтобы не переключать раскладку клавиатуры
- Статистика
- Попробовать рисовать статистику через графики egui.
- Где-то должно быть окошко чтобы посмотреть просто количество всех слов в системе, количество выученных слов и количество изучаемых слов
- Для каждого дня запоминается:
- Сколько слов сегодня отработано по полной
- Сколько попыток совершено вообще, сколько правильных, сколько неправильных
- Сколько задолженность на сегодня
- Сколько слов сегодня добавили
- Как долго была включена программа (простои больше 15 секунд не учитываются)
- Можно получить статистику за всё время, суммировав статистику за каждый день
отсортировать
#3Планирование структур данных и функций
Только теперь, когда имеется некое видение программы, можно начать пытаться писать код. Если писать код без этапа сбора и систематизации идей, то можно забыть некоторые мелочи, которые потом придётся вставлять с большой болью.
И начинать код лучше всего не с написания действий, а с проектирования типов/структур данных и сигнатур функций. Под структурами данных я понимаю не списки, деревья итд, а просто enum'ы и struct'ы. Я даже где-то слышал такую фразу:
Найти нужную структуру данных — это уже значит решить половину задачи.
И я очень согласен с этим высказыванием, действительно то как ты будешь решать всю задачу зависит от того как выглядят твои типы, особенно важную роль играют enum'ы, которые прям очень хорошо описывают предметную область.
И поэтому я не могу понять как можно программировать на языках с динамической типизацией, где никто типы никогда не пишет. Я вообще не понимаю какой профит даёт избавление от типов, ведь в долгую это огромный проигрыш, и в короткую тоже не вижу выигрыша.
Мой ответ на вопрос о том зачем нужны типы, отлично иллюстрируется цитатой Коннора МакБрайда, тоже очень известного теоретика в области ЯП. Он в трэде жалуется на то что последние 20-30 лет писали ЯП таким образом чтобы типы сами выводились из программы, тогда как можно было делать всё наоборот: можно было писать типы, из которых потом выводятся программы. Мне кажется что это очень глубокая мысль. И, честно говоря, когда я это осознал, то очень сильно поменял своё отношение к тому как пишу код. Потому что ведь на самом деле типы — это идеальная проекция вашей доменной модели приложения на код, которая всегда будет актуальней кода, потому что если она внезапно перестаётся быть актуальной, то код не тайп-чекается. И это с моей точки зрения самое главное — написать крутой, корректный, правильный тип, насколько хорошо позволяет ваш ЯП. Даже если у вас не очень мощные типы, всегда есть возможности спроектировать вашу систему так, чтобы типы там отражали вашу доменную область наилучшим образом. Тогда процесс имплементации становится делом техники. В Idris'е даже есть момент: если вы правильно написали тип, то код может вывестись сам. Но в реальной жизни, когда мы не используем такие ЯП, как правило, когда есть хороший тип, то вы просто пишите банальный код и всё очень просто и понятно. И это мой ответ на то зачем же нужны типы.

Ещё есть идея, что чтобы удобнее было писать код, надо подумать о том как представить данные в том виде, чтобы задача в них решалась максимально естественно, и перевести их в этот формат:


png
Далее я буду кидаться коммитами, начинающимися с @. Мне кажется что оптимальным способом смотрения их будет: открыть в новой вкладке и пролистать diff, увидеть примерно что произошло. Либо можно просто их игнорировать, особо ничего не потеряете. Смотреть что происходило в коммитах может быть полезно если вам нужны прям детали как происходила моя разработка.
Спустя два коммита (@a8549a3, @b79f219) и 1ч 20м, у меня получились следующие типы, которые далее будут являться основой всего:
/// Итерация изучения слова, сколько ждать с последнего изучения, сколько раз повторить, показывать ли слово во время набора
struct LearnType {
/// Сколько дней ждать с последнего изучения
wait_days: i8,
count: i8,
show_word: bool,
}
/// Статистика написаний для слова, дня или вообще
struct TypingStats {
typed: i32,
right: i32,
wrong: i32,
}
/// Обозначает одну пару слов рус-англ или англ-рус в статистике
enum WordStatus {
/// Мы знали это слово раньше, его изучать не надо
KnowPreviously,
/// Мусорное слово, артефакт от приблизительного парсинга текстового файла или субтитров
TrashWord,
/// Мы изучаем это слово
ToLearn {
translation: String,
/// Когда это слово в последний раз изучали
last_learn: Day,
/// Количество изучений слова, при поиске того что надо печатать, проходим по всему массиву
learns: Vec<LearnType>,
/// Статистика
stats: TypingStats,
},
/// Мы знаем это слово
Learned {
translation: String,
/// Статистика
stats: TypingStats,
},
}
struct WordsSaved(BTreeMap<String, Vec<WordStatus>>);
В эти структуры сразу было заложено много идей, в том числе статистика. Когда я писал этот код, то очень много перечитывал все идеи, сверялся с тем чтобы ничего не потерялось, и всё было учтено с самого начала.
Следующим этапом приступил к планированю структур и методов для графического интерфейса. Я пишу интерфейс через ImGui, про который написал отдельную статью. Поэтому на интерфейс у меня потратится минимально времени, и планировать его максимально легко.
Интерфейс распланировал за 32м: @0cab890, и после этого планирования даже чуть-чуть улучшились и основные структуры данных.
#3Написание кода
Далее за 1ч написал код логики: @96eb608.
Затем за 2ч 45м написал код интерфейса до минимально рабочего состояния: @7b8de3d.
Кстати, писать работающий код поверх распланированных функций и типов крайне приятно, код так легко и быстро идёт.
Итак, на отметке чистого времени у нас 6ч 16м, и программа выглядит следующим образом:
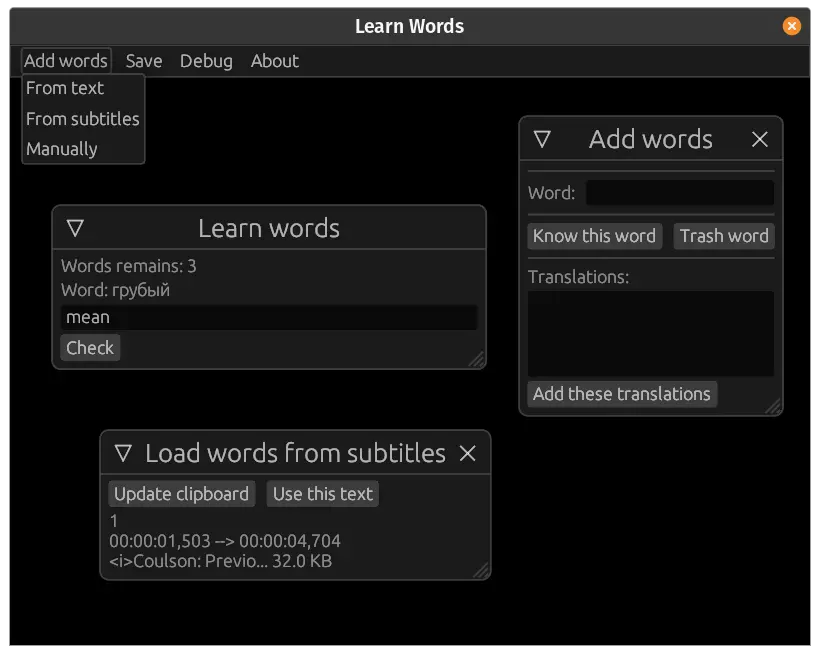
png
Здесь работает всего три окошка и основной функционал.
#3Todo-листы
Итак, я написал самый минимальный прототип. По идее им уже можно пользоваться.
Нам больше не настолько нужен файлик с идеями, удаляем оттуда всё реализованное: (он стал совсем маленьким)
@47b0669/ideas.md diff
идеи неизвестной полезности
- Чтобы при добавлении слов замерялась их частотность, даже частотность известных, и она просто суммировалась к тому что уже хранится, чтобы можно было видеть частотность выученных слов. Хотя и для этого придётся какой-то сложный интерфейс пилить.
- Интерфейс добавления слова
- Чтобы для данного слова можно было видеть его контекст использования
- Интерфейс ввода слова
- Есть кнопочка
(i)напротив каждого слова, на которую можно нажать и посмотреть статистику этого слова
- Есть кнопочка
- Интерфейс статистики слова
- Когда добавлено (дата, количество дней назад)
- Сколько раз вводилось
- Сколько правильно, сколько неправильно
- Все майлстоуны (дней после добавления)
И заводим файлик todo, в котором разместим конкретные todo-пункты для выполнения:
@47b0669/learn_words.todo diff
общее:
✔ сделать чтобы по интерфейсу написания слова можно было легко перемещаться @done (21-07-29 23:34)
✔ чтобы субтитры могли возвращать ошибку и она показывалась в окне @done (21-07-29 23:41)
☐ сделать чтобы перемещение по интерфейсу ввода слова делалось через enter
☐ добавить чтобы каждое слово знало свой текущий уровень
☐ чтобы из файла считывалась комбинация (Words, Settings), и чтобы она же сохранялась
☐ замер времени в программе
+ когда простой мышки или клавиатуры больше 15 секунд, программа переходит в режим паузы, и прекращает замер времени, и это показывается на весь экран
+ время в программе за сегодня показывается снизу
+ каждый день запоминается количество времени в програме
раскладка:
☐ сделать окно для раскладки клавиатуры
+ галочка "использовать автопереключение раскладки", и если галочка отмечена, то далее показывается всё что есть
+ введите все свои английские символы
+ введите все свои русские символы
+ если ввести символ не можешь, значит ставить пробел
+ чтобы чекалось если вдруг из двух разных языков находятся одинаковые символы, тогда отвергать такую раскладку
+ можно ставить enter для удобства
+ сравнивалось количество символов без enter, и говорилось когда они совпадают а когда нет
+ кнопка "использовать эту раскладку"
☐ сделать виджеты поля ввода, которое умеет определять текущую раскладку и язык ответа и автоматически подменять буквы
☐ раскладка должна храниться в settings
статистика:
☐ статистика количества слов в программе:
+ известные
+ мусорные
+ изучаемые на каждый уровень
+ изученные полностью
☐ основа для замера каждый день
+ замерять количество попыток
+ новых неизвестных слов
+ обновляется либо вручную, либо при закрытии программы, либо при открытии окна статистики
+ заодно замерять количество попыток вообще
☐ показывать статистику за сегодня внизу
☐ запоминание количества слов каждого уровня каждый день
☐ плитка как на гитхабе
+ можно выбирать какой параметр показывать, учитывая всё что известно для текущего дня
☐ график количества запомненных слов за все дни, условно какую площадь он занимает, со stems
васм:
☐ хранение в куках
☐ заюзать quad_rand
☐ при закрытии вкладки чтобы автоматически сохранялся прогресс
☐ кнопки для считывания и загрузки своих данных в программу в меню в пункте Data -> {Import, Export}
Тут стоит отвлечься насчёт того как я веду todo-списки. Одни люди это делают через GitHub, другие через приложение на телефон, а я через расширение для текстового редактора. Я пишу в Sublime + PlainTasks, так же есть похожее расширение для VSCode: Todo+.
Учтите, что этот файл выглядит очень хорошо только в Sublime + PlainTasks, от markdown здесь никакого форматирования к сожалению не делается.
Теперь далее можно реализовывать по одному пунктику и сразу видеть результат.
Я обязательно держу все свои задачи в туду-пунктах. Если бывает так что я выполнил что-то, чего там нет, то я просто заношу это текстом и потом сразу отмечаю как сделанное, за это мой мозг даёт какой-никакой дофамин.
Ещё у меня есть .todo файлик для каждого проекта, и я все эти файлики храню в одном месте, ибо коммитить его в проект странно; а хранить его в папке проекта и скрывать через .gitignore — плохо, обязательно потеряется.
У меня даже есть туду-файлы для жизни, для медицины (по каким врачам сходить) и так далее. Очень удобная самоорганизация.
#3Обычный цикл разработки
Теперь я выполняю туду-пункты и потихоньку коммичу изменения от них. Пока выполняю одни пункты, в голову могут приходить идеи других, и их тоже заношу в туду. Что-то совсем радикальное заношу в файлик ideas.md, чтобы не забыть, но и не заставлять себя реализовывать.
На таймере чистого времени 21ч 21м и следующий результат:
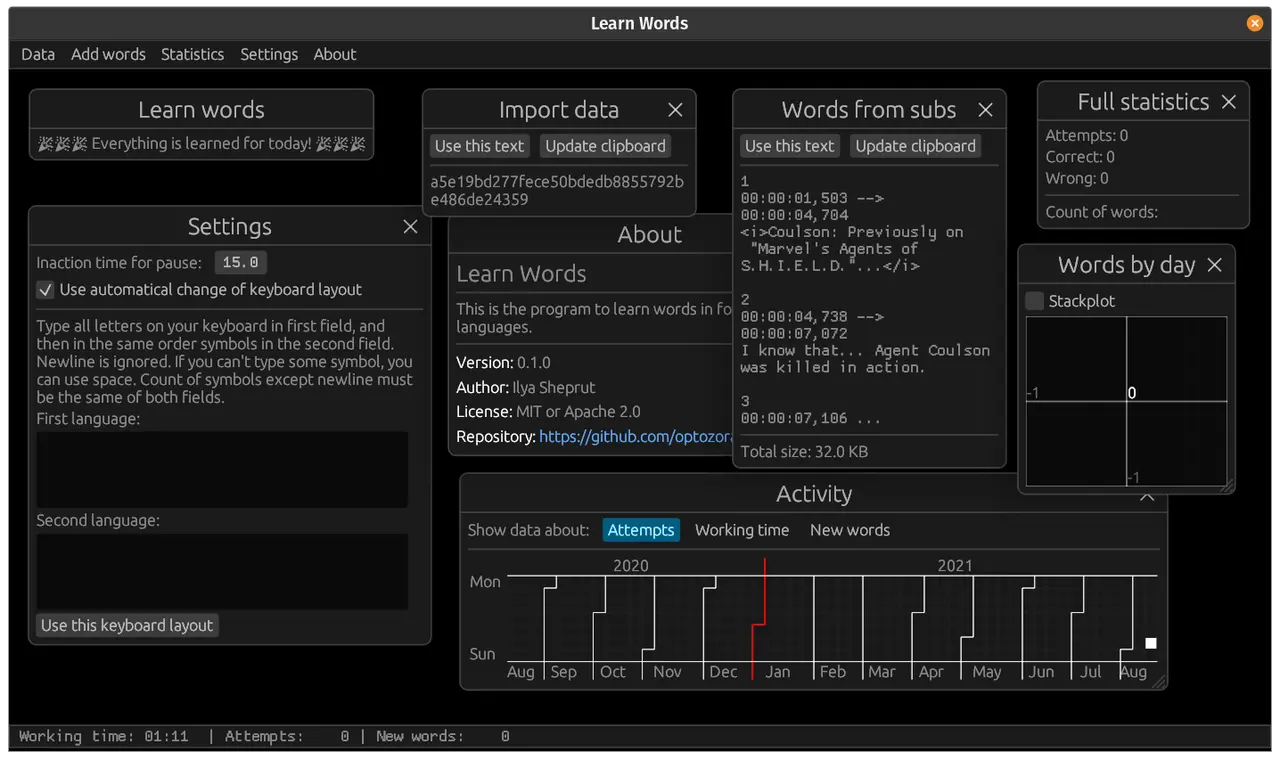
png
Тут уже намного больше фич, и я сам полноценно начал пользоваться программой. Но во время пользования очень много начало болеть и я записал ещё больше туду-пунктов.
На таймере 33ч 23м чистого времени и я публикую статью про эту програму.
На моменте 41ч я публикую вторую версию, которая, можно сказать, является финальной версией. Больше от программы мне ничего не нужно, все основные туду-пункты я выполнил.
Программу можно считать завершённой.
#3Куда девать выполненные туду-пункты
На данный момент я сделал почти всё, а в файлике с туду-пунктами очень много строк, которые отмечены как выполненные или как отменённые. Когда их становится слишком много, я просто переношу их все вниз в раздел «Архив». Я не удаляю строки, чтобы просто не терять информацию, и просто потому что приятно видеть как много работы я сделал. Конечно, я переношу выполненное вниз не только когда завершаю проект, а когда пунктов становится слишком много, такое периодически происходит в некоторых моих проектах. Посмотреть на текущий туду-файл можно здесь:
@42b5e72/learn_words.todo link
общее:
☐ для stackplot сделать чтобы самые маленькие по площади были в самом низу, а самые большие в самом вверху
статьи:
✔ рассказать о quad-storage @done (21-08-10 21:52)
☐ написать статью о том как сделал эту прогу
☐ 1 сентября опубликовать статью по результатам месячного использования этой проги
далёкая перспектива:
☐ https://github.com/emilk/egui/issues/595
☐ в зависимости от того что выключается в stackplot в легенде, убирать это из вычислений, для этого надо внедрить фичу в egui
рефакторинг:
✔ причесать функцию ui, вынести поля ввода со всеми их фичами в отдельную функцию, чтобы не было этого копипаста, а данные в отдельную структуру @done (21-08-10 19:27)
☐ для того чтобы тратилось меньше памяти, и прога работала быстрее за счёт уменьшения числа аллокаций, использовать айдишники строк, а все строки хранить в одной структуре
☐ переделать так, чтобы в words хранился не массив, где слово может быть выученным и подлежащем изучению, а чтобы сверху там было (trash, known, (learn, и вот уже внутри learn массив (либо выученное, либо изучаемое))) (сомнительное удобство)
☐ попытаться заюзать gat
-------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------
АРХИВ:
-------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------
общее:
✔ сделать чтобы по интерфейсу написания слова можно было легко перемещаться @done (21-07-29 23:34)
✔ чтобы субтитры могли возвращать ошибку и она показывалась в окне @done (21-07-29 23:41)
✔ добавить чтобы каждое слово знало свой текущий уровень @done (21-07-30 14:18)
✔ чтобы из файла считывалась комбинация (Words, Settings), и чтобы она же сохранялась @done (21-07-30 14:23)
✔ замер времени в программе @done (21-07-30 15:01)
+ когда простой мышки или клавиатуры больше 15 секунд, программа переходит в режим паузы, и прекращает замер времени, и это показывается на весь экран
+ время в программе за сегодня показывается снизу
+ каждый день запоминается количество времени в програме
✔ сделать чтобы перемещение по интерфейсу ввода слова делалось через enter @done (21-07-31 23:24)
✔ сделать базовое окно about @done (21-07-31 23:35)
✔ кажется на васме протекает буфер обмена при использовании русских символов. видимо путаются количество чаров и длина в байтах, надо пофиксить @done (21-08-01 00:10)
раскладка:
✔ сделать окно для раскладки клавиатуры @done (21-07-30 19:30)
+ галочка "использовать автопереключение раскладки", и если галочка отмечена, то далее показывается всё что есть
+ введите все свои английские символы
+ введите все свои русские символы
+ если ввести символ не можешь, значит ставить пробел
+ чтобы чекалось если вдруг из двух разных языков находятся одинаковые символы, тогда отвергать такую раскладку
+ можно ставить enter для удобства
+ сравнивалось количество символов без enter, и говорилось когда они совпадают а когда нет
+ кнопка "использовать эту раскладку"
✔ сделать виджеты поля ввода, которое умеет определять текущую раскладку и язык ответа и автоматически подменять буквы @done (21-07-30 19:30)
✔ раскладка должна храниться в settings @done (21-07-30 19:30)
статистика:
✔ основа для замера каждый день @done (21-07-30 15:34)
+ замерять количество попыток, правильных и неправильных
+ новых неизвестных слов
+ обновляется либо вручную, либо при закрытии программы, либо при открытии окна статистики
+ заодно замерять количество попыток вообще
✔ показывать статистику за сегодня внизу @done (21-07-30 15:34)
✔ запоминание количества слов каждого уровня каждый день @done (21-07-30 15:34)
✔ статистика количества слов в программе: @done (21-07-30 16:23)
+ известные
+ мусорные
+ изучаемые на каждый уровень
+ изученные полностью
+ вычисляется при вызове программы из words
✔ график количества запомненных слов за все дни, условно какую площадь он занимает, со stems, по уровням @done (21-07-30 17:40)
✔ аналогично верхнему график количества правильных и неправильных попыток @done (21-07-30 17:40)
✔ плитка как на гитхабе @done (21-07-30 23:36)
+ можно выбирать какой параметр показывать, учитывая всё что известно для текущего дня
васм:
✔ кнопки для считывания и загрузки своих данных в программу в меню в пункте Data -> {Import, Export} @done (21-07-30 18:03)
✔ заюзать quad_rand @done (21-07-31 14:51)
✔ хранение в куках @done (21-07-31 22:20)
+ https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Client-side_web_APIs/Client-side_storage
✔ попробовать скомпилить под васм @done (21-07-31 23:12)
✔ при закрытии вкладки чтобы автоматически сохранялся прогресс @done (21-07-31 23:12)
рефакторинг:
✔ сделать trait ClosableWindow, и функцию process_window, которая обрабатывает окно, которое может закрыться, чтобы не копипастить это постоянно. или лучше структуру, которая оборачивается вокруг структуры окна, умеет закрываться, сама конструирует окно, и сама в функции ui отслеживает когда окно хотят закрыть @done (21-07-30 16:06)
критичное:
✔ если просто нажимать кнопку мыши без движения, то выскакивает пауза @done (21-08-02 21:20)
✔ для того чтобы читать буфер обмена, пользователь должен сам нажать ctrl+v, тогда мб убрать автоматическое считывание буфера обмена, аналогично для ctrl+c @done (21-08-02 21:54)
✔ подсказки должны даваться с пробелом, а то из-за курсора их не видно @done (21-08-02 21:55)
✔ чтобы автосохранение было после каждого слова @done (21-08-02 21:56)
✔ если нажать use this text с пустым текстом, то происходит паника, file: "src/main.rs", line: 1185, col: 38 @done (21-08-02 22:01)
✔ кажется в копипасте нельзя вставить текст длиньше 32768 символов @done (21-08-02 22:37)
✔ переделать настройки количества изучения, чтобы они не копипастились в каждое слово, а были глобальны @done (21-08-02 23:12)
+ тогда надо чтобы это можно было задавать в окне settings
сделать следующим:
✔ при вводе слова с подсказкой необходимо вводить не только перевод слова, но и его самого. это нужно, потому что я пытаюсь ускориться, и не читаю что за слово с подсказкой я пишу @done (21-08-03 17:22)
✔ наверное за сессию надо изучать меньше слов, а не все добавленные. сделать настройку, которая позволяет взять N (пусть для начала будет 20) слов в пул, и изучать их, и только когда они кончатся, изучать дальше. @done (21-08-03 17:48)
✔ окно-редактор-просмотрщик слов, где можно искать слова fuzzy поиском, где сразу отображается внутренность @done (21-08-03 20:20)
✔ автоматическое открытие окна просмотрщика слов, где фильтрование происходит по текущему добавленному слову @done (21-08-03 20:20)
✔ окно для редактирования одного слова @done (21-08-03 22:16)
✔ сделать карандашик напротив слова, которое открывает окно для этого слова и позволяет его редактировать @done (21-08-03 22:16)
✔ всё-таки добавить фичу, показывающую контекст конкретного слова, заодно показывать частоту его встречи в данном тексте @done (21-08-03 23:02)
✔ должна быть возможность выбирать количество новых слов, и количество слов для повторения @done (21-08-04 14:57)
✔ после добавления текста или субтитров должно показываться окно с инфой: @done (21-08-04 17:20)
+ всего слов
+ уникальных слов
+ отфильтровано
+ известные (known, trash, learned)
+ изучаемые (tolearn)
+ неизвестных
✔ синхронные субтитры, когда одновременно показывается и русский и английский вариант @done (21-08-04 23:51)
✔ разобраться с выделением текста при поиске @done (21-08-04 23:55)
✔ чтобы когда в вводе ничего нет, или нашлись новые результаты, скролл улетал на начало @done (21-08-04 23:57)
✔ 0 всегда обозначает отсутствие скролла @done (21-08-04 23:57)
✔ сделать чтобы скролл целился на лейбл только после нажатия кнопки @done (21-08-04 23:57)
✔ убрать массив в поиске слова @done (21-08-05 00:03)
✘ вынести общую часть в коде find_whole_word @cancelled (21-08-05 00:14)
✔ сделать чтобы нулевой элемент не показывался в кнопочках, и чтобы не выделялся, и чтобы на него нельзя было попасть @done (21-08-05 00:14)
✔ в окне добавления слова может унести контекст вправо @done (21-08-05 13:52)
✔ возможность менять масштаб в настройках @done (21-08-05 14:02)
✔ должна быть галочка, позволяющая двигать график @done (21-08-05 14:19)
✔ нужна белая тема, ибо на тёмной глазам неприятно @done (21-08-05 14:35)
+ запоминать тему в настройки
+ рисовать всё окно белым или чёрным в зависимости от темы
+ запомнить цвета для всяких штук типо activity в зависимости от темы
✔ заюзать нормальный рандом, который инициализируется текущим временем @done (21-08-05 19:22)
✔ после ввода какого-то слова неправильно, надо его снова ввести с подсказкой, и переходить дальше не разрешит, пока правильно не напишешь @done (21-08-10 16:34)
+ после неправильного ввода слова его надо снова написать даже несколько раз
✔ пропускать окно проверки для ввода с подсказкой @done (21-08-10 16:34)
✔ после ввода слова должна быть возможность инвертировать правильный и неправильный результаты @done (21-08-10 16:34)
+ чтобы там использовалось right_to_left
+ для этого надо регистрировать попытки не после их ввода, а после нажатия кнопки "next"
✔ чтобы если нажимается backspace на пустом поле или кнопке, фокус запрашивался назад @done (21-08-10 17:54)
✘ перевести Words на хранение двух разных языков, и при выборе слов для набора считать только английские слова @cancelled (21-08-10 18:21)
✘ сортировать слова для добавления не по их алфавитному написанию, а по порядку как они встречаются в тексте, чтобы лишний раз не читать одни и те же предложения @cancelled (21-08-10 21:51)
---
✔ в окне add words должно быть поле где можно добавлять известные переводы этого слова @done (21-08-10 18:12)
✔ сделать кнопку для скипа добавляемых слов @done (21-08-10 18:12)
✔ нужна возможность отменить предыдущее нажатие при добавлении слова, а то так можешь быстро нажимать что знаешь слово и раз, пропустил одно @done (21-08-10 18:12)
+ запоминать одно слово, и удалять его из words методом для удаления, если нажалась кнопка back
---
✔ сделать чтобы при выборе слов добавлялись сразу переводы, и выбор останавливался когда набиралось больше чем нужное количество, или все слова кончались @done (21-08-10 19:02)
✔ в первую очередь должны выбираться наиболее старые слова в окне выбора слов @done (21-08-10 19:02)
✔ писать сколько осталось набрать это слово сегодня @done (21-08-10 19:12)
✔ чтобы на кнопке при нажатии backspace отправляло назад @done (21-08-10 19:16)
✔ должна быть кнопка отмены текущего набора и выбора количества слов для изучения @done (21-08-10 19:26)
✔ наверное лучше сначала набрать все слова, которые ты не знаешь с подсказкой, в рандомном порядке, а уже затем набирать все слова которые надо без подсказки набирать причём надо сделать не просто выбор рандома, а чтобы нормально shuffle'ился весь массив, аналогично всё остальное, чтобы подряд не шло два раза одно и то же слово никогда @done (21-08-10 19:46)
---
✔ чтобы при переименовании перевода, перевод тоже переименовывался нормально @done (21-08-11 18:15)
✔ сохранять всё после изменения слова @done (21-08-11 18:15)
✔ в окне edit word должна быть возможность удалять конкретный перевод слова, и добавлять новые, в окне выставления дня должно автоматически ставиться сегодняшний день @done (21-08-11 18:25)
---
✔ чтобы через настройки можно было задавать уровни и количество повторений. @done (21-08-11 18:39)
---
✔ сделать чтобы текущий день считался локальным, а то у меня в 0:00 день был не сегодняшний @done (21-08-11 19:04)
✘ законтрибьютить user_dpi в egui-miniquad @cancelled (21-08-11 19:27)
✘ мб попробовать отображать панику на экране @cancelled (21-08-11 19:27)
✔ баг: не все слова выбираются когда выбираешь для повторения то, что не имеет перевода для повторения @done (21-08-11 23:02)
---
✔ перейти на egui-web, egui-glium @done (21-08-11 22:25)
✔ добавить возможность скачивать экспорт как файл @done (21-08-12 14:58)
✘ добавить кнопку, которая выделяет всё @cancelled (21-08-12 14:58)
---
✔ оптимизировать цвета в белой теме, мб через отдельное окно @done (21-08-13 19:18)
✘ заставить в вебе работать изменение масштаба @cancelled (21-08-13 20:24)
не криитчное:
✔ кажется нативное приложение не хочет сохранять статистику в файл @done (21-08-01 23:06)
✔ кажется окно добавления слов не фильтрует известные слова @done (21-08-01 23:12)
✔ невозможно нажать пробел из-за замены символов @done (21-08-02 21:06)
✔ слова должны быть огромными, а не простой label @done (21-08-02 21:06)
✔ чтобы слова можно было удалять @done (21-08-03 23:15)
✘ при вводе слова должна быть возможность посмотреть его статистику @cancelled (21-08-03 23:15)
✘ при вводе в попытках слова должна быть возможность отредактировать это слово (типо иногда оставил лишнее окончание или что-то такое) @cancelled (21-08-03 23:15)
✔ в окне добавления слов по тексту показывать сколько было уникальных, а сколько отфильтровалось @done (21-08-05 14:35)
✔ добавить learned translations в окно добавления слов @done (21-08-05 14:36)
✘ в github стате затемнять на dim 0 те элементы где 0 @cancelled (21-08-05 14:39)
✘ должна быть возможность добавлять алиасы для какого-то слова, типо если ты его ввёл не так, чтобы оно считалось тоже правильным. @cancelled (21-08-11 19:04)
+ тогда должна быть кнопка после ввода слова, которая не только отменяет неверность текущего ответа, но и одновременно добавляет его в алисы
+ это не нужно, так как есть кнопка invert
#2Время работы над этой программой
Кстати, если вам интересно сколько времени было потрачено на каждый пункт этой программы, то эта информация находится здесь в файле ниже. Замер времени коммитился одновременно с написанием какой-то фичи, так что дополнительную информацию можно отследить по коммитам и blame.
@aba59d5/video.md link
информация
- (во времени не учитывается время на написание статей)
- время написания первых идей: 20 минут
- время их ситематизации: 20 минут
- планирование структур данных, связанных с основной логикой, без учёта интерфейса: 1 час 20 минут
- планирование структур и методов интерфейса: 32м (2:32)
- написание кода основной логики: 1 час (3:32)
- написание кода интерфейса до минимально рабочего состояния: 2ч 45м (6:16)
6ч 16м-------------------------------------------------- Минимально рабочее состояние- сделал два пункта и распланировал дальнейшие идеи в todo: 45м (7:02)
- слетел таймер
- три общих пункта: 47м (0:47)
- основа статистики: 34м (1:21)
- рефакторинг окон: 30м (1:51)
- реализация статистики и других мелких улучшений: 1ч 53м (3:44)
- раскладка клавиатуры: 1ч 4м (4:48)
- github-like плитка: 3ч (7:44)
- написал quad-storage: 1ч 49м (9:33)
- заставил запускаться в васме, пофиксил баги и небольшие дополнения: 1ч 50м (11:23)
- скинул таймер
- написание статьи про программу: 2ч 56м
21ч 21м-------------------------------------------------- Средне рабочее состояние- закончил править все критичные пункты: 1ч 30м
- начал таймер
- сделал чтобы можно было выбирать количество слов: 44 минуты (0:44)
- сделал чтобы можно было искать по всем словам с fuzzy поиском и это работало при добавлении слова: 1ч 2м (1:46)
- сделал окно для редактирования одного слова: 53м (2:39)
- добавил показ контекста данного слова из текста: 46м (3:15)
- для работы можно выбирать количество новых слов и количество слов для повторения: 21м (3:36)
- добавил вывод информации о количестве слов в тексте после добавления: 20м (3:56)
- фича синхронных субтитров: 3ч 26м (7:22)
- мелкие фичи: 57м (8:19)
- переход на другой генератор рандома: 10м (8:29)
- сбросил таймер
- дописал статью про программу с учётом новых фич и пользования: 2ч 3м
33ч 23м-------------------------------------------------- Первый релиз- повторение слов после неправильного ввода и инвертирование результатов: 1ч 48м
- улучшения окна add words: 20м
- выбор переводов при выборе слов и выбор наиболее задолженных слов: 43м
- улучшения набора слова: 45м
- улучшения окна edit word: 30м
- задание количества повторений в настройках: 11м
- чтобы текущий день считался правильно с учётом тайм-зоны: 37м
- переехал на egui_template: 2ч 13м
- написал про второй релиз: 30м
41ч-------------------------------------------------- Второй релиз- добавил скачивание статистики в виде файла: 1ч 15м
- оптимизировал цвета в белой теме: 1ч 2м
- не смог заставить в вебе работать изменение масштаба: 1ч
- написание статьи про imgui: 2ч 44м
- написание статьи про то как пишу программы: 1ч
#2Пример сложной фичи
В программе была одна очень сложная фича, реализацию которой интересно рассмотреть отдельно. Эта фича синхронных субтитров. Её суть в том чтобы можно было загрузить одновременно русские и английские субтитры, и смотреть их параллельно.
Когда дело доходит до такой сложной фичи, её надо хорошо продумать.
Ещё фичу надо не только хорошо продумать, но и додуматься до того чтобы её внесение в программу давалось минимальными усилиями, чтобы пришлось минимально переделать. Изначально я хотел внести эту фичу как часть окна по добавлению слов из субтитров, но понимал что это будет требовать для каждых английских субтитров иметь русские, что плохо вписывалось. Тогда я додумался просто сделать эту фичу как отделное окно, и всё сразу стало красиво.
Вот результат продумывания в файлике ideas.md:
@80a5703/ideas.md diff
...
синхронные субтитры
- это будет отдельное окно, которому можно указывать конкретное слово, а оно будет их искать все его встречи в первом предоставленном тексте
- окно для добавления имеет два поля для ввода текста: Lang 1 (to search words), Lang 2 (translation of Lang 1).
- у окна для показывания есть метод, который позволяет ввести в поиск нужное слово, если окно открыто. в отличие от окна поиска, это окно не открывается автоматически
- использует column для окна вставки субтитров
- использует grid для показывания параллельно. так как там могут быть пустые места с обоих сторон.
- использует код аналогичным scrolling для выбора элемента скролла
- перебирает одновременно оба субтитра и смещает указатель текущего времени, если у текущего времени есть пересечение с тем что на другом языке, связывает их в один
- ещё в окне показывается номер элемента слева, то есть grid состоит из 3 элементов
- если одна фраза на одном языке пересекается с несколькими на другом языке, то она показывается только для первой
- есть галочка искать по словам или по вхождениям
...
В процессе стало понятно что эта фича больше похожа на олимпиадную задачу, чем на обычный код. Проблема в том, что субтитры не обязаны мне ничего. У меня нет гарантий, что одна реплика идёт за другой, и что в английском и русском фразы обязательно будут иметь одинаковые тайминги. И это надо было учитывать.
Сначала я планировал алгоритм в случае того что субтитры выглядят хорошо. На картинке ниже время идёт справа-налево, снизу русские субтитры, сверху английские.
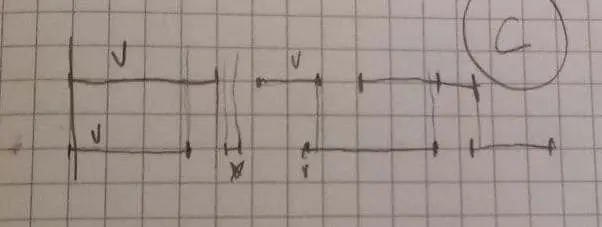
jpg
Затем выбрал худший общий вариант и начал планирвоать алгоритм субтитров как на картинке. Всё аналогично предыдущей, только английский и русский язык разделяет волнистая линия. Видно, что тут нарушается гарантия того что в одном файле субтитров все реплики обязаны идти друг за другом.
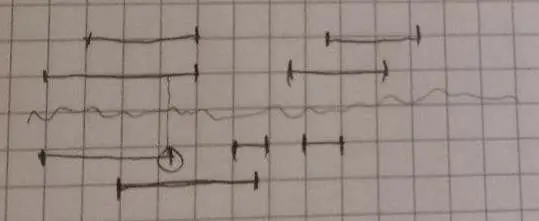
jpg
Тут очень пригождаются навыки олимпиадного программирования, ибо надо:
- Рассмотреть крайние случаи.
- Узнать какие у тебя есть гарантии от входных данных, увидеть подвох.
- Постараться продумать алгоритм без костылей, чтобы на его реализацию не ушло больше часов, чем длится олимпиада.
- Чтобы алгоритм работал за приемлемое время.
Но я решил забить на скорость работы алгоритма, ибо у меня не миллиарды реплик, а максимум тысяча. И я искал каждую подходящую реплику тупо линейным поиском. И на практике никаких замедлений при добавлении синхронных субтитров не наблюдается.
Так что крайне советую вам прокачаться в олимпиадном программировании на codeforces. LeetCode фигня, ибо он плохо замеряет время работы программы, и вообще задачки там слабые.
Кстати я использую бумагу только когда надо что-то рисовать или писать математические формулы, в других случаях писать текст на клавиатуре в миллион раз быстрее. Так что лично я советую вам писать идеи и туду-пункты не на бумаге.
#2Про чистое время
Я замерял время работы и можно увидеть что чистого времени получилось 40 часов, что это значит? Это значит что я бы мог сделать эту программу за рабочую неделю? Нет.
Моё чистое время замерялось только во время работы, перерывы я не засчитывал. Ещё я работал не по 8 часов в день, а меньше: иногда 2, иногда 4. И самое главное — между этими подходами у меня были большие перерывы в виде отдыха и сна. Так что это может быть причиной почему я так эффективно работал.
На работе мы работаем с перерывами, итого за 8 часов рабочего дня, из них по-настоящему рабочими получается всегда меньше. Говорят, 4-6.
Да и даже если захотеть, и каждый день работать по 8 часов идеально, чтобы все эти 8 часов были чистым временем, то так долго не протянешь. Устанешь уже на следующий день. А если не устанешь, то в долговременной перспективе тебя ждёт выгорание и проблемы с психическим здоровьем.
Так что все эти инициативы по переходу на 4-часовой или 6-часовой рабочий день имеют смысл.
#На примере фичи для Portal Explorer
Это пример про то как я внёс непростую фичу в другую програму.
У меня стояла задача сделать возможность добавить камере переключение между разными точками, чтобы заранее эти точки можно было задать, а пользователь мог между этим выбором переключаться. Это нужно было для предстоящих сцен.
Эта фича оказалось одной из тех, для которых у меня не было ни малейшего понятия о том как её реализовывать.
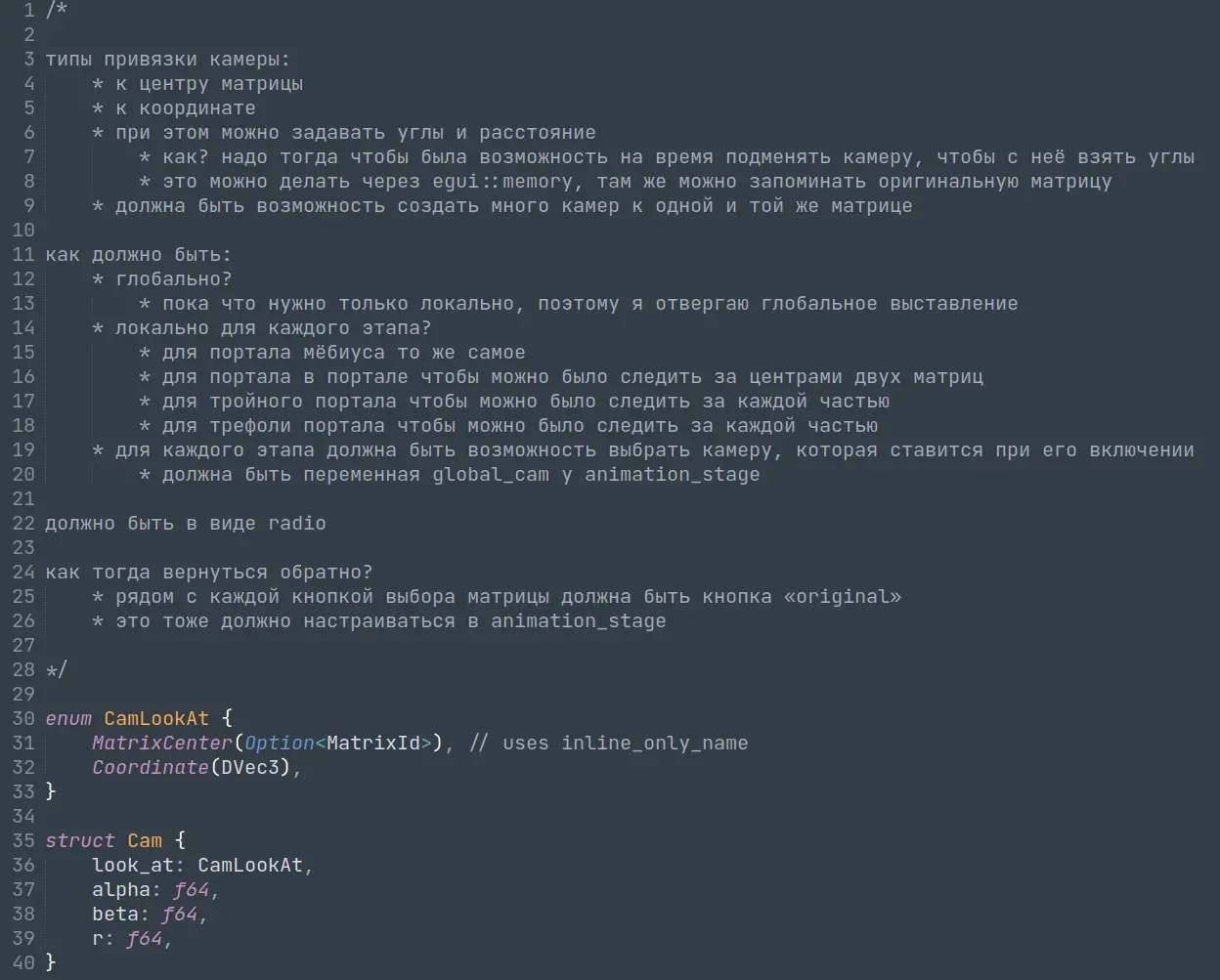
Поэтому сначала я взял и начал расписывать вопросы и ответы на них. Здесь самое главное — продумать как фича встанет в имеющуюся структуру программы. Я рассуждал в форме текста. Когда появилось первое понимание — накидал struct'урки и enum'ы. Наблюдать результат рассуждений и типы можно на скриншоте ниже:
png
После этого ещё больше подумал, проработал все непонятные места и разрешил их, в голове сложилась картина, и я решил записать туду-пунктики, которые надо реализовать, чтобы эта фича была полностью сделана — это второй скриншот.

png
Теперь, после того как у меня всё чётко и понятно в голове, я мог начать очень эффективно фигачить код,.
И затем код был благополучно реализован. Конечно, пару штук на планировании я забыл, но без этого никуда.
#Про пет-проекты
Немного мыслей про то как делать пет-проекты, кажется что они подходят духу статьи.
#2Поиск аналогов
Моя программа для изучения слов похожа на другую программу — Anki. Я это узнал только после написания своей программы, поэтому хочу чтобы вы не повторяли моих ошибок.
Тщательней ищите аналоги, изучайте их досконально, читайте статьи и пользуйтесь. Ведь, как известно, самый лучший проект — это тот, который не пришлось сделать.
Если бы я удосужился нормально искать программы для изучения слов, а не удовлетвориться неудобством Duolingo и ему подобных, то я бы и не потратил всё это время на написание своей программы, я бы мог написать только отдельный модуль для работы с субтитрами, например.
Ну или если ваша задача в том чтобы научиться какой-то технологии через пет-проект, то этот совет неприменим, тут писать очередной велосипед — святое дело.
#2Важнее что-то не делать
Просто процитирую tonsky:
Давайте расскажу вам про главное правило пет-проектов. Главное правило пет-проектов: придумать, как ничего не делать.
Многие программисты могут подумать, что ничего не делать — это что-то автоматизировать. Нет, наоборот, автоматизирование добавляет головной боли, а мы хотим ее избежать. Например, мне в прошлом посте про «пассивный код — мертвый код» порекомендовали не мучать пользователя постоянными разлогинами, а завести тестового юзера и автоматизировать:
«Скрипты. Планировщик в CI запускает тесты, оформленные в pytest/junit/whatever, рисует красивые картинки, срёт уведомлениями, если что-то пошло не так. Надо только определиться, кто отвечает за реакцию на уведомления.»
Это, конечно, путь для нормальных систем, где программистам платят зарплату, чтобы они не дергались и делали то, что сами добровольно никогда бы делать не захотели.
Но в пет-проектах, к сожалению, зарплату не платят, поэтому приходится адаптироваться. Что не так с этим предложением?
Во-первых, очень много работы. Скрипты надо написать, всю эту машинерию — настроить. Во-вторых, очень много мейнтенанса — за CI надо следить, на уведомления реагировать. В-третьих, это все будет ломаться, это надо обслуживать, что явно будет лень делать, т.к. ломается оно всегда не вовремя, а проектом не каждую неделю есть время заниматься.
Трюк с пет-проектами в том, чтобы обмануть себя и успеть сделать что-то, что можно показать людям до того, как ты устанешь и тебе надоест. А тебе устанет и надоест, trust me. Поэтому количество нерелевантной работы надо резать жестко и беспощадно. И поэтому я так доволен решением с авторизацией: работы нет, а тестирование выполняется.
Классическая иллюстрация этого принципа это «не пишите движок блога». Потому что устанете быстрее, чем напишете первый пост. Люди, которые хостятся на Github Pages с готовым шаблоном или на Wordpress — те, которым интересно решить проблему; люди, которые пишут движок — те, которым интересно попрокрастинировать. Поэтому вы читаете этот текст в Телеграмме, а не на каком-то самописном сайте с собственным компилятором — я бы этот компилятор до сих пор писал.
Другой пример из недавнего — Roam Research. Чуваки лет то ли пять, то ли семь сидят без сервера вообще, тупо складывают все в Firebase и ничего, работают, денег подняли. Во всей инфраструктуре нет ни одного сервера. Потом пришел создатель Athens Research, решил склонировать Roam, но еще больше не заморачиваться, и не стал делать даже Firebase. Просто сделал локального клиента, так еще и без авторизации обошелся. И все равно 2 ляма поднял. Легенда.
Все это иллюстрирует один принцип: чем меньше работы вы себе придумаете, тем выше шансы все это закончить. И наоборот, будете делать «по-нормальному», «правильно» — и не закончите никогда. Потому что лето, пиво, дети, диван, друзья или плейстейшн побеждают «отдых программированием» в 100% случаев. Да вообще все что угодно его побеждает. И это нормально, с этим ничего не сделаешь, надо просто придумать, как в таких условиях работать.
#2Прототипирование
На первых этапах нужно реализовать как можно меньше фич, чтобы видеть результат и был шанс довести проект до конца, иначе вы выгорите, если для того чтобы увидеть первый результат вам потребуется 40ч чистого времени. Затем надо вносить только самые критичные фичи, чтобы снова видеть результат, и понимать что программа в любой момент времени выполняет максимальное число функций, которые вы от неё хотите.
Ещё крайне важно делать результат быстро и сразу им пользоваться, ибо потребность в некоторых фичах невозможно понять пока не попользуешься.
Поэтому ImGui здесь отлично заходит для прототипов или пет-проектов. Он ускоряет разработку.
#2Сразу отбрасывать сложные фичи
Как мне удалось так быстро сделать программу для изучения английских слов?
Потому что на самом начальном этапе я откинул самые сложные фичи:
- Иметь встроенный словарь
- Нормализация слов (убрать -s, -ing, -ed итд.)
- Retained mode интерфейс
Благодаря этому я тратил время только на войну с собой. Не воюя с другими библиотеками.
Такие вещи надо заранее откидывать, иначе ты никогда не закончишь свой проект. Вначале всё должно быть тупо и вручную.
Если ваш проект предполагает что-то очень сложное, что невозможно выкинуть, то советую подумать о том стоит ли вам браться за этот проект, или прямо сейчас делать что-то попроще.
#Автоматизация
Щас хайпятся всякие GitHub Copilot, которые типо пишут код за программистов, и типо бу-бу-бу программистов заменят машины.
Посмотрите на эту статью ещё раз. Разве такое можно автоматизировать? Это настоящее мышление, которое требуется для программирования даже джуном. Это нельзя автоматизировать до тех пор, пока не будет создан сильный ИИ. А до тех пор Copilot будет только инструментом, который немного упрощает разработку в руках программиста.
А когда создадут сильный ИИ, то отпадёт смысл в любом человеческом труде на планете Земля, так что нет смысла волноваться конкретно за программистов. Все станем бесполезными вместе.
#Заключение
Этот способ не идеален, это скорее сборник идей, чем инструкция к действию каждый раз. Надеюсь эта статья натолкнёт вас на поиск своего способа планировать программы, который увеличит вашу эффективность.